
Junhong Shen
Ph.D. Student
Carnegie Mellon University
Advisor: Ameet Talwalkar
Email Google Scholar GitHub Twitter
Bio
I’m a 5th-year Ph.D. student in the Machine Learning Department at CMU, advised by Ameet Talwalkar. My work centers on enhancing LLM’s interaction with real-world applications, in particular building multi-modal models and agent systems that operate in real-world environments, such as browsers, command lines, and IDEs. I’m also interested in enhancing LLMs’ abilities to model diverse data types and applying them to long-tail, low-resource domains such as science and business.
I obtained my B.S. in Mathematics of Computation at UCLA, where I was fortunate to work with Lin Yang on sample-efficient reinforcement learning. I have also worked on multi-agent RL and Theory of Mind, advised by Song-Chun Zhu and Ying Nian Wu. My PhD is supported by JP Morgan AI PhD Fellowship.
I'm on the industry job market, seeking research scientist positions! Feel free to email me if there's a fit! Here's my CV.
News
- Oct 2025: My intership work at DeepMind on code generation agent for visual reasoning is out!
- Sep 2025: Our work on scaling Test-Time Interaction is accepted by NeurIPS 2025!
- Apr 2025: We are organizing the CMU Agent Workshop again this year. Check out and participate!
- Dec 2024: My internship work at FAIR is released! Check out Content-Adaptive Tokenizer (CAT) and Multi-Modal Mixture-of-Mamba!
- Nov 2024: Check out our newest work on web agents built on top of open-source LLMs! ScribeAgent paper, code, and blog post.
- Sep 2024: Grateful to be awarded the J.P. Morgan AI PhD Fellowship (accepted) and the Bloomberg PhD Fellowship (declined)!
- May 2024: My internship work at Microsoft Research, Tag-LLM, is accepted by ICML 2024!
- Apr 2023: Our work on cross-modal fine-tuning is accepted by ICML 2023 as oral presentation!
- Oct 2022: We are organizing the 2022 AutoML Decathlon. Check out and participate!
Selected Publications
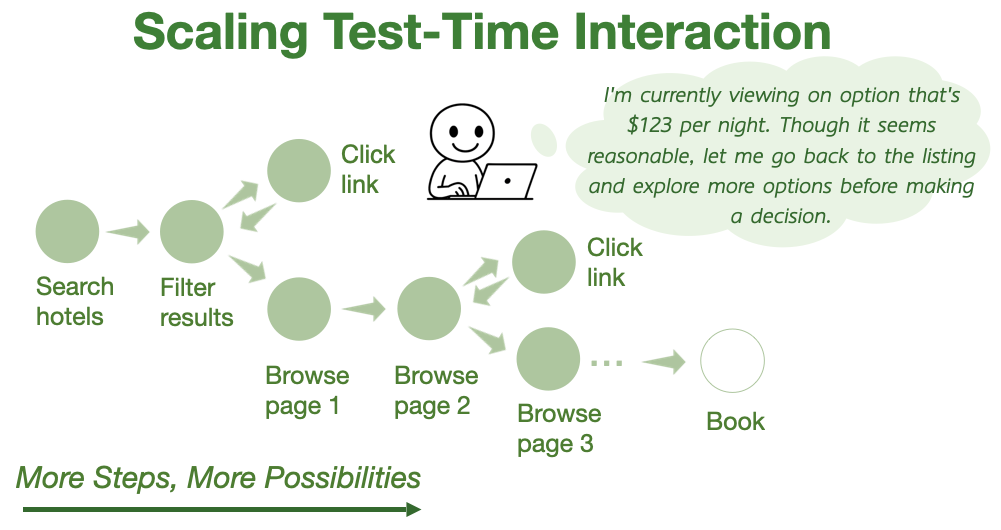
Thinking vs. Doing: Agents that Reason by Scaling Test-Time Interaction

CAT: Content-Adaptive Image Tokenization
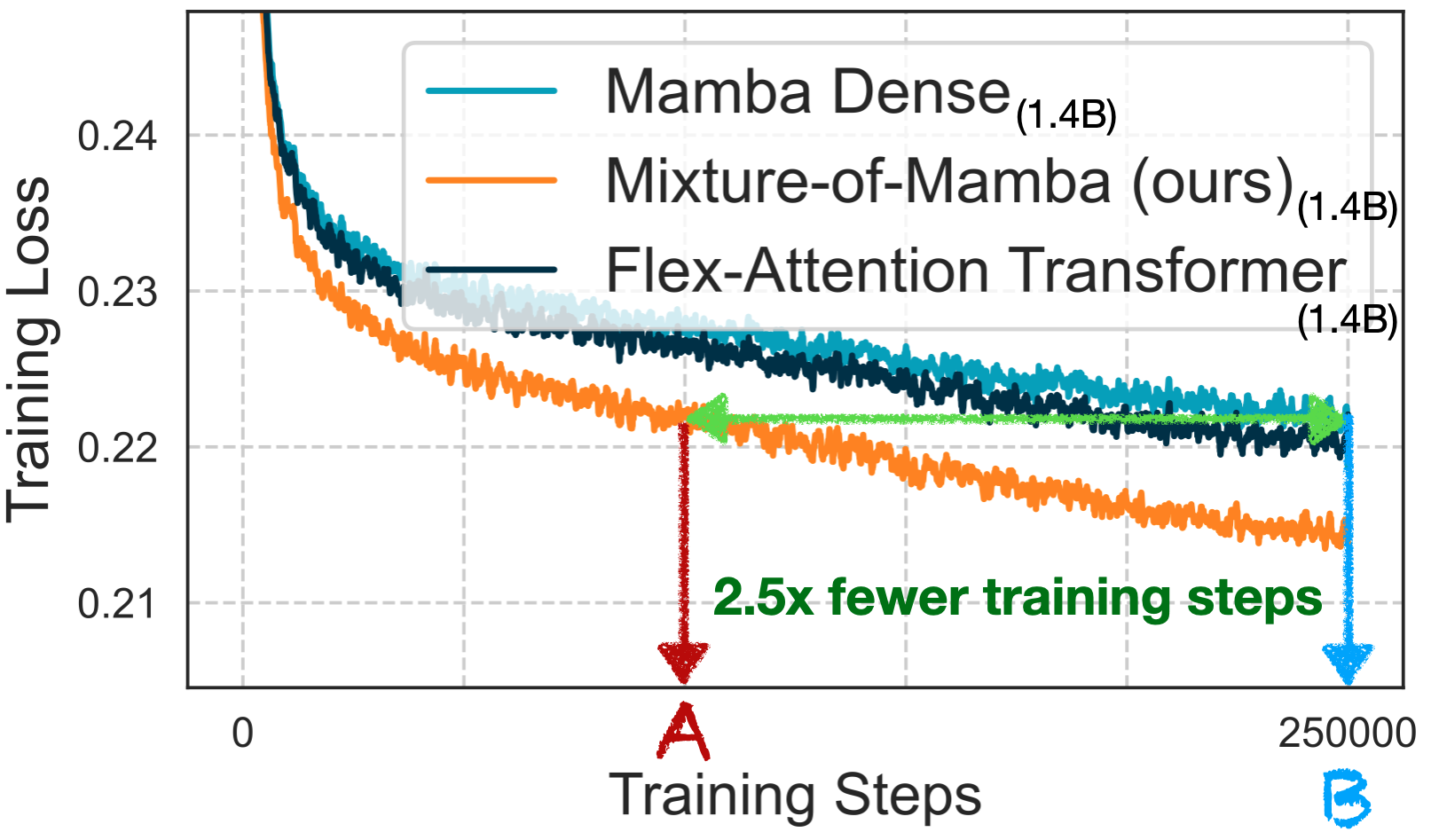
Mixture‑of‑Mamba: Enhancing Multi‑Modal State‑Space Models with Modality‑Aware Sparsity
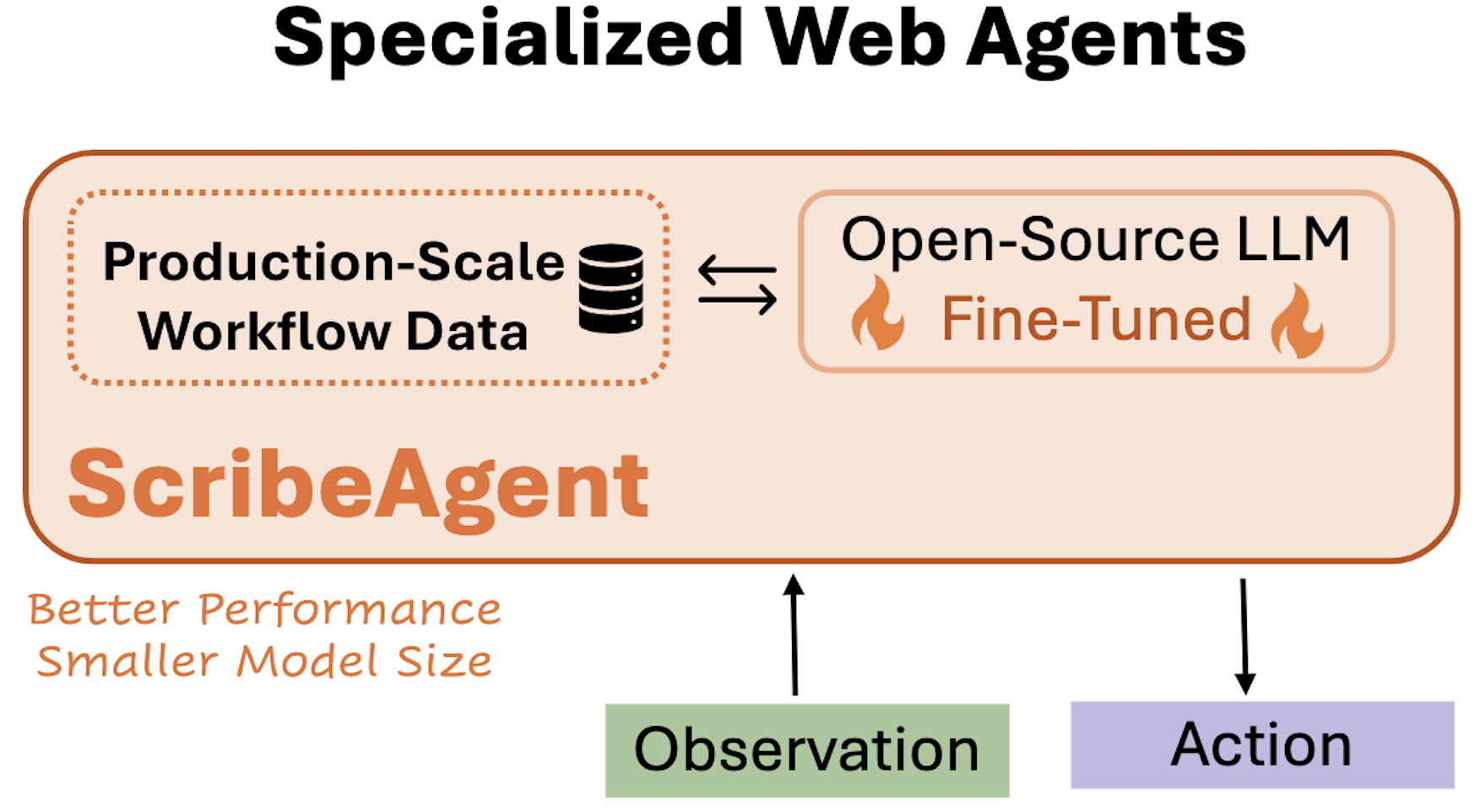
ScribeAgent: Towards Specialized Web Agents Using Production-Scale Workflow Data
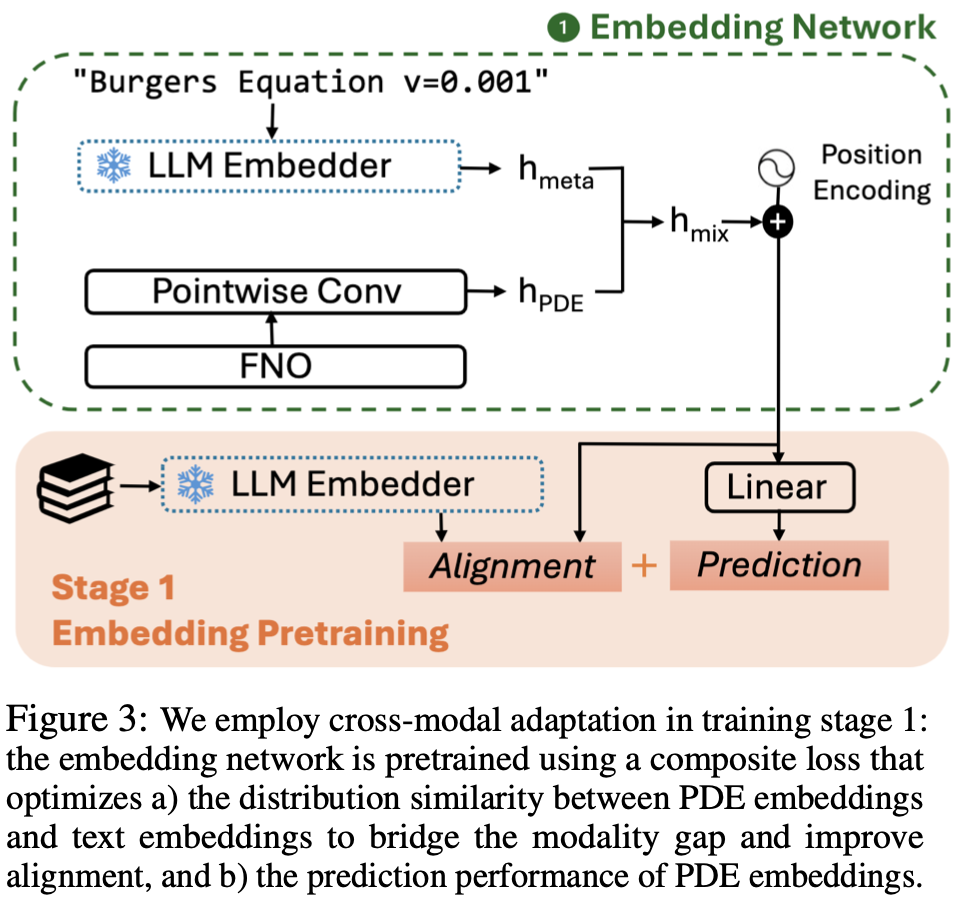
UPS: Efficiently Building Foundation Models for PDE Solving via Cross-Modal Adaptation
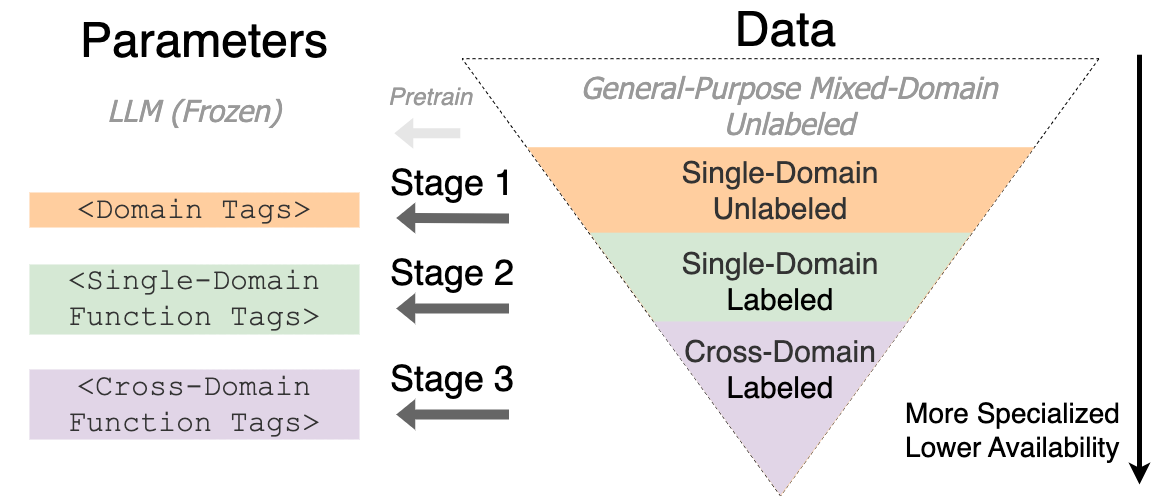
Tag-LLM: Repurposing General-Purpose LLMs for Specialized Domains
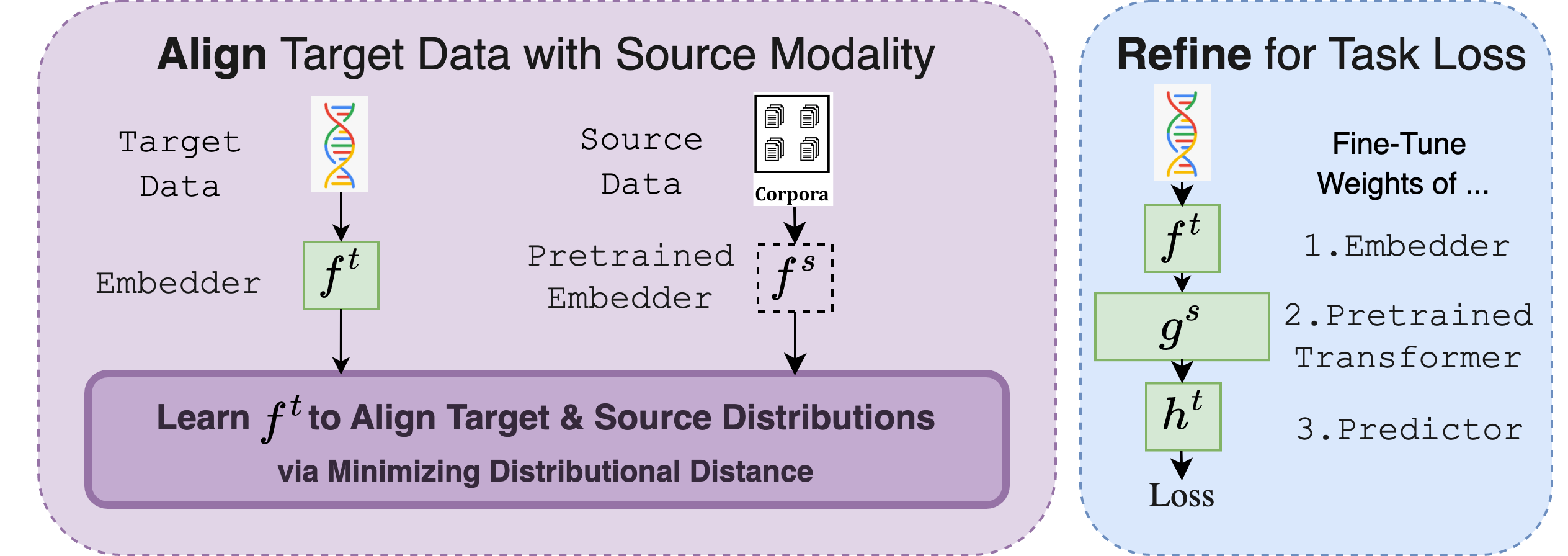
Cross-Modal Fine-Tuning: Align then Refine
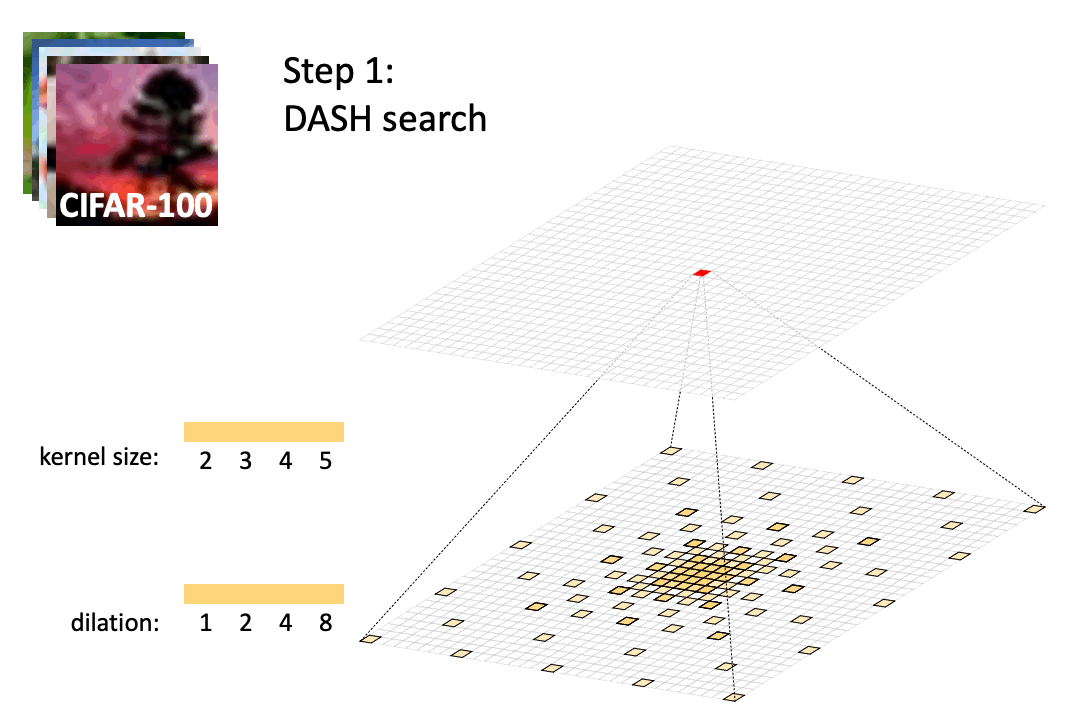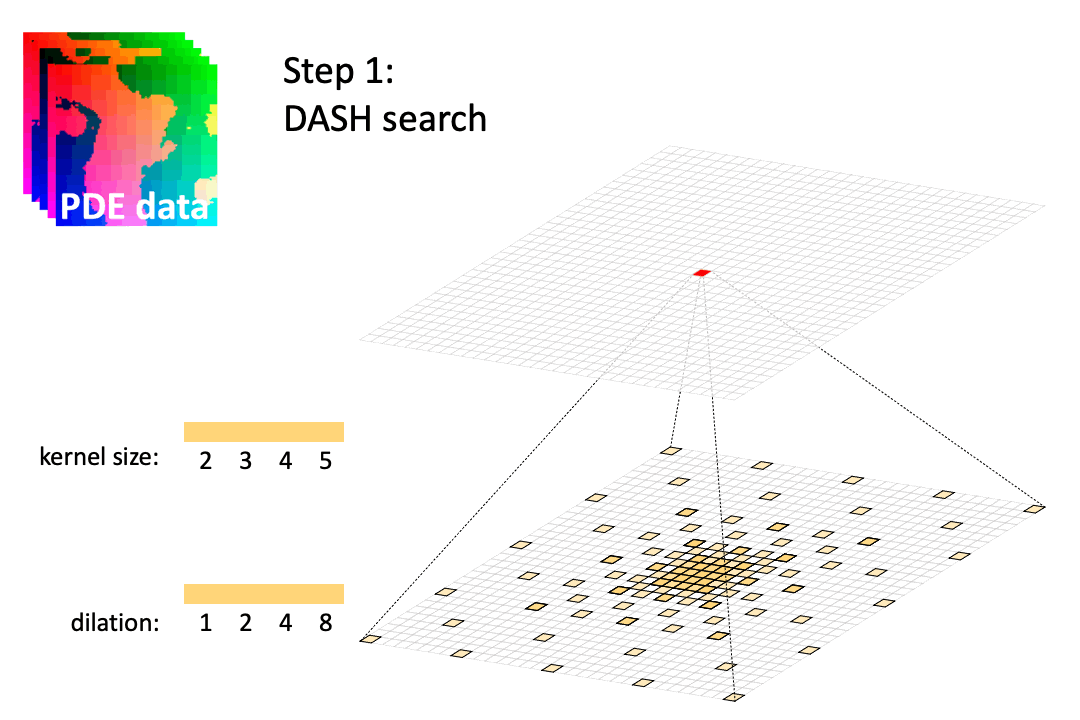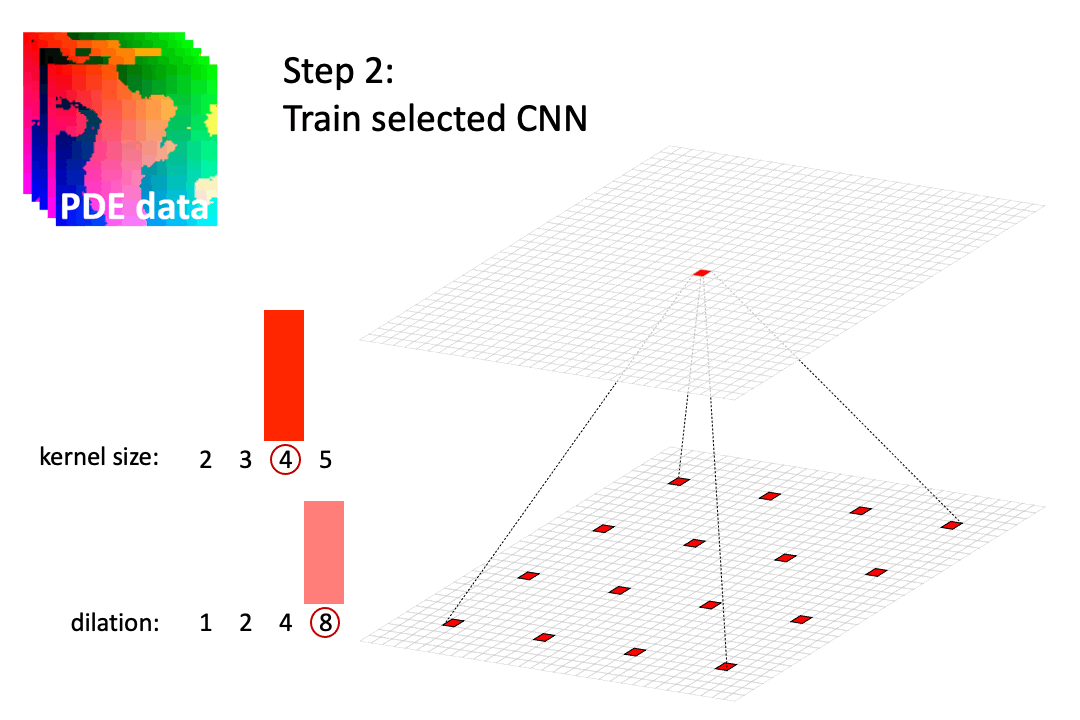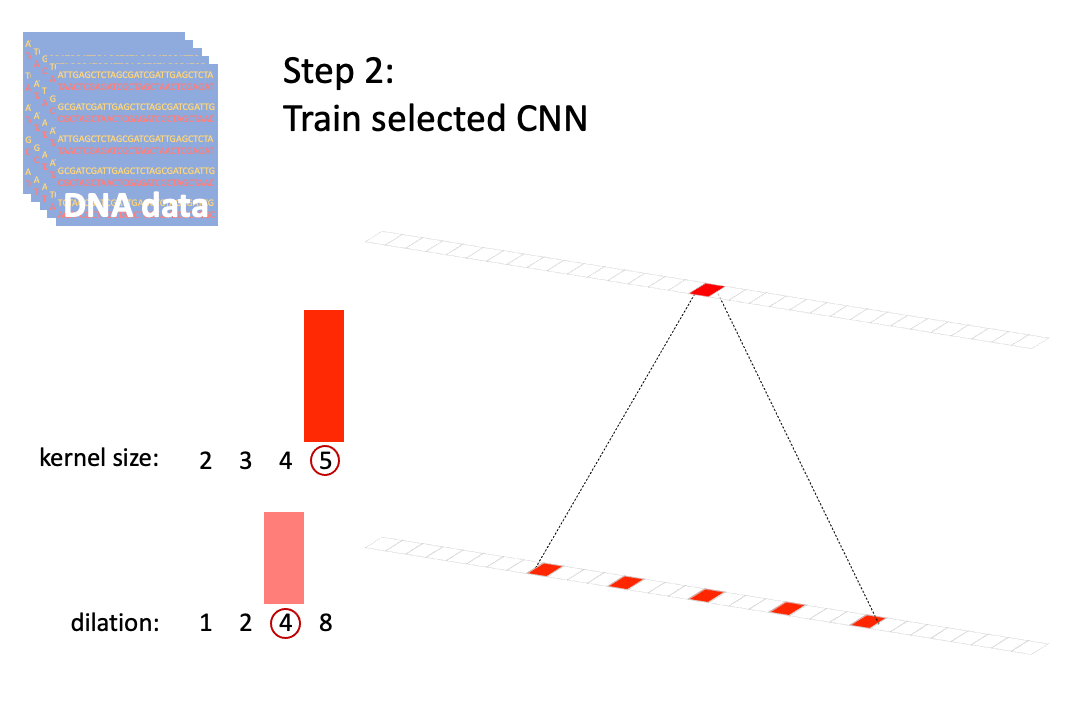
Efficient Architecture Search for Diverse Tasks
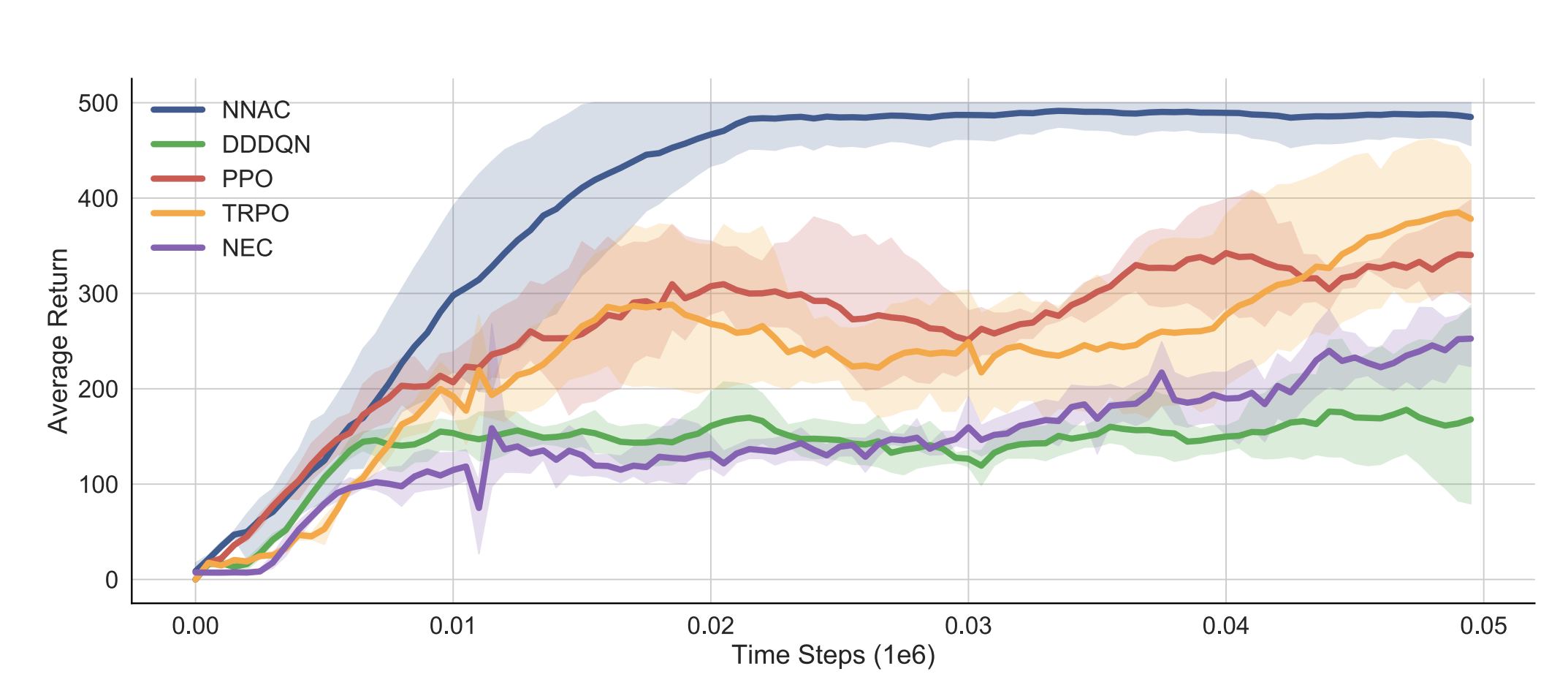
Theoretically Principled Deep RL Acceleration via Nearest Neighbor Function Approximation
Cite Thinking vs. Doing: Agents that Reason by Scaling Test-Time Interaction
@misc{shenbai2025tti,
title={Thinking vs. Doing: Agents that Reason by Scaling Test-Time Interaction},
author={Junhong Shen and Hao Bai and Lunjun Zhang and Yifei Zhou and Amrith Setlur and Shengbang Tong and Diego Caples and Nan Jiang and Tong Zhang and Ameet Talwalkar and Aviral Kumar},
year={2025},
eprint={2506.07976},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2506.07976},
}Cite Mixture‑of‑Mamba: Enhancing Multi‑Modal State‑Space Models with Modality‑Aware Sparsity
@misc{liangshen2025mixtureofmamba,
title={Mixture-of-Mamba: Enhancing Multi-Modal State-Space Models with Modality-Aware Sparsity},
author={Weixin Liang and Junhong Shen and Genghan Zhang and Ning Dong and Luke Zettlemoyer and Lili Yu},
year={2025},
eprint={2501.16295},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2501.16295},
}Cite CAT: Content-Adaptive Image Tokenization
@misc{shen2024adaptivetokenizer,
title={CAT: Content-Adaptive Image Tokenization},
author={Junhong Shen and Kushal Tirumala and Michihiro Yasunaga and Ishan Misra and Luke Zettlemoyer and Lili Yu and Chunting Zhou},
year={2025},
eprint={2501.03120},
archivePrefix={arXiv},
primaryClass={cs.CV},
}Cite ScribeAgent: Towards Specialized Web Agents Using Production-Scale Workflow Data
@misc{shen2024scribeagent,
title={ScribeAgent: Towards Specialized Web Agents Using Production-Scale Workflow Data},
author={Junhong Shen and Atishay Jain and Zedian Xiao and Ishan Amlekar and Mouad Hadji and Aaron Podolny and Ameet Talwalkar},
year={2024},
eprint={2411.15004},
archivePrefix={arXiv},
primaryClass={cs.CL},
}Cite UPS: Efficiently Building Foundation Models for PDE Solving via Cross-Modal Adaptation
@misc{shen2024ups, title={UPS: Efficiently Building Foundation Models for PDE Solving via Cross-Modal Adaptation},
author={Junhong Shen and Tanya Marwah and Ameet Talwalkar},
year={2024},
eprint={2403.07187},
archivePrefix={arXiv},
primaryClass={cs.LG}
}Cite Tag-LLM: Repurposing General-Purpose LLMs for Specialized Domains
@misc{shen2024tagllm,
title={Tag-LLM: Repurposing General-Purpose LLMs for Specialized Domains},
author={Junhong Shen and Neil Tenenholtz and James Brian Hall and David Alvarez-Melis and Nicolo Fusi},
year={2024},
eprint={2402.05140},
archivePrefix={arXiv},
primaryClass={cs.LG}
}Cite Cross-Modal Fine-Tuning: Align then Refine
@misc{shen2023orca,
author = {Shen, Junhong and Li, Liam and Dery, Lucio M. and Staten, Corey and Khodak, Mikhail and Neubig, Graham and Talwalkar, Ameet},
title = {Cross-Modal Fine-Tuning: Align then Refine},
publisher = {ICML},
year = {2023},
url = {https://arxiv.org/abs/2302.05738}
}Cite Efficient Architecture Search for Diverse Tasks
@inproceedings{shen2022efficient,
title={Efficient Architecture Search for Diverse Tasks},
author={Shen, Junhong and Khodak, Mikhail and Talwalkar, Ameet},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2022}
}Cite Theoretically Principled Deep RL Acceleration via Nearest Neighbor Function Approximation
@inproceedings{Shen2021TheoreticallyPD,
title={Theoretically Principled Deep RL Acceleration via Nearest Neighbor Function Approximation},
author={Junhong Shen and Lin F. Yang},
booktitle={AAAI},
year={2021}
}